
DevOps and Data Management Tools for Salesforce
|
The thesis behind Cubic Compass Navigator is simple:
"The faster data is imported into Salesforce, the sooner it's used." Cubic Compass Navigator was developed over 15+ years by a group of Salesforce Architects and Developers to automate the tedious tasks of loading data, deploying records, running mass updates, backing up data, and taking metadata snapshots. The toolset has literally shaved thousands of hours off of projects. Over $1B in annual revenue is processed through Navigator data lakes, tasks, and pipelines. The core features of data tools are
|
|
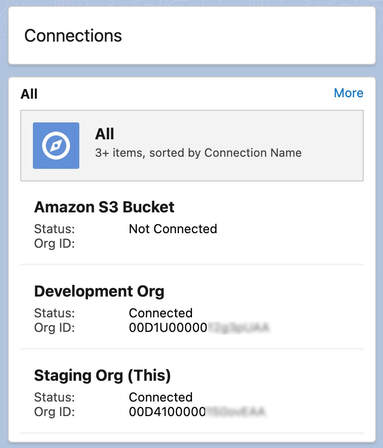
Connections
|
Connections form the basis of authenticating and moving data around. The org in which data tools are installed is established as the "Task Org", or sometimes referred to as the "Hub" org. The "Connections" tab manages several connections. Many data task types define source and target connections.
Types of connections supported:
|
|
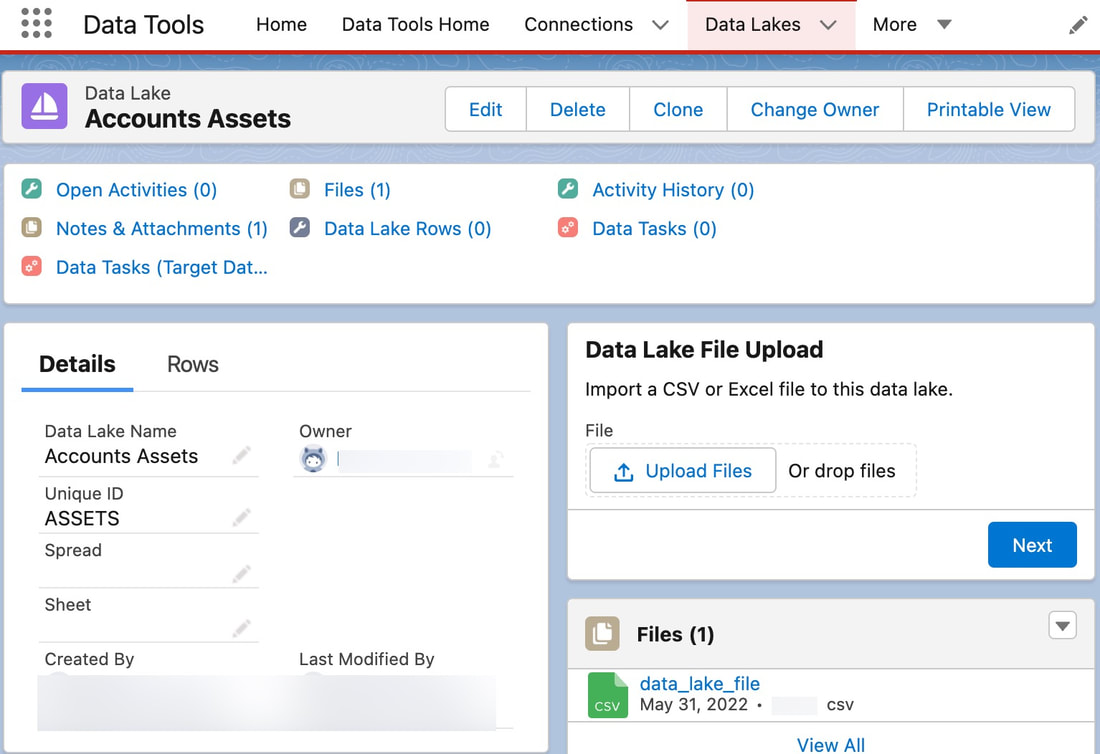
Data Lakes

|
All Cubic Compass data migrations and pipelines are designed and engineered to be repeatable. Data lakes provide a temporary, unstructured storage for use in staging data prior to transformation and loading.
ELT Architecture Data Lakes support an ELT architecture, or "Extract, Load, and Transform". This helps to avoid dependencies on spreadsheets and manual data loader processes for enterprise-scale integrations. This also keeps raw data in the cloud closer to their ultimate destination. The extract and load steps are typeless and schema-less. This allows raw data in any format to be successfully loaded into Salesforce where it awaits processing in the data lake. Transformation processes then convert the raw data lake rows into Salesforce records, importing based on parent-child lookup dependencies. Intelligent Resource Management Data Science and Ops Team responsibilities are often formed around data lake principles, such that one role is solely responsible for generating and uploading flat files into the Salesforce data lake, and another team is responsible for reviewing, cleansing, and accepting data lake rows into Salesforce. No More Excel VLOOKUPs! Data Lakes remove the tedious task of Excel based VLOOKUPs to determine record parent IDs. Parent-child relationships are automatically mapped during migration data tasks to auto-resolve 18-character lookup IDs. |
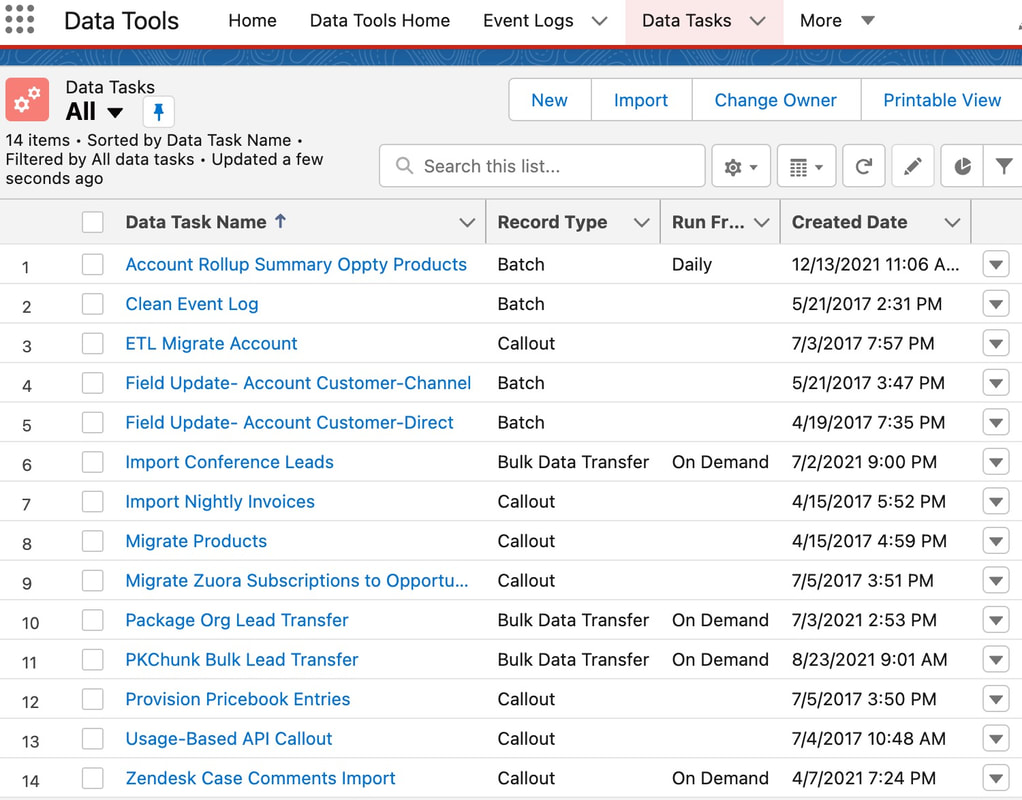
Data Tasks and Pipelines
|
A unit of work is a "Data Task". Many data tasks can be orchestrated in series or parallel to create "Data Pipelines".
Common data tasks include:
|
|
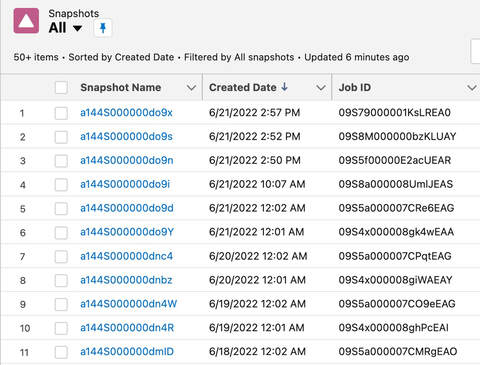
Metadata Snapshots
|
Cubic Compass supports both automated and manual metadata snapshots. The metadata can be utilized in:
|
Deployments
|
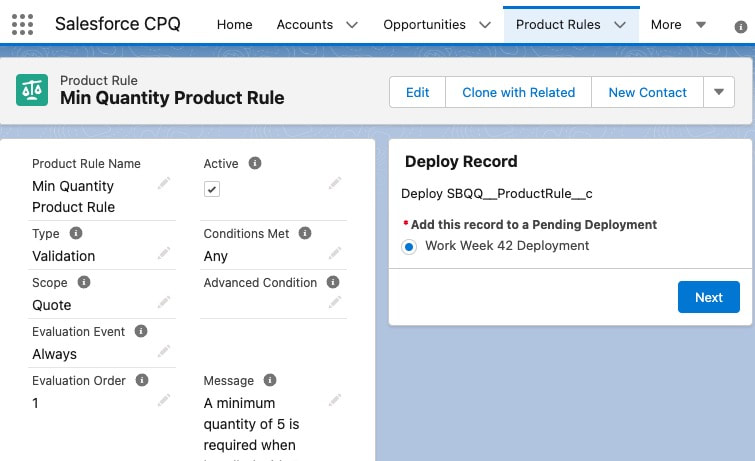
Developed originally for CPQ configuration deployments, Cubic Compass supports the deployment of any standard or custom object record in any source-to-target org connection configuration.
This enables development team to configure products, price rules, product rules, and discount schedules in a sandbox development org, then deploy the records to production. This results in:
|
|
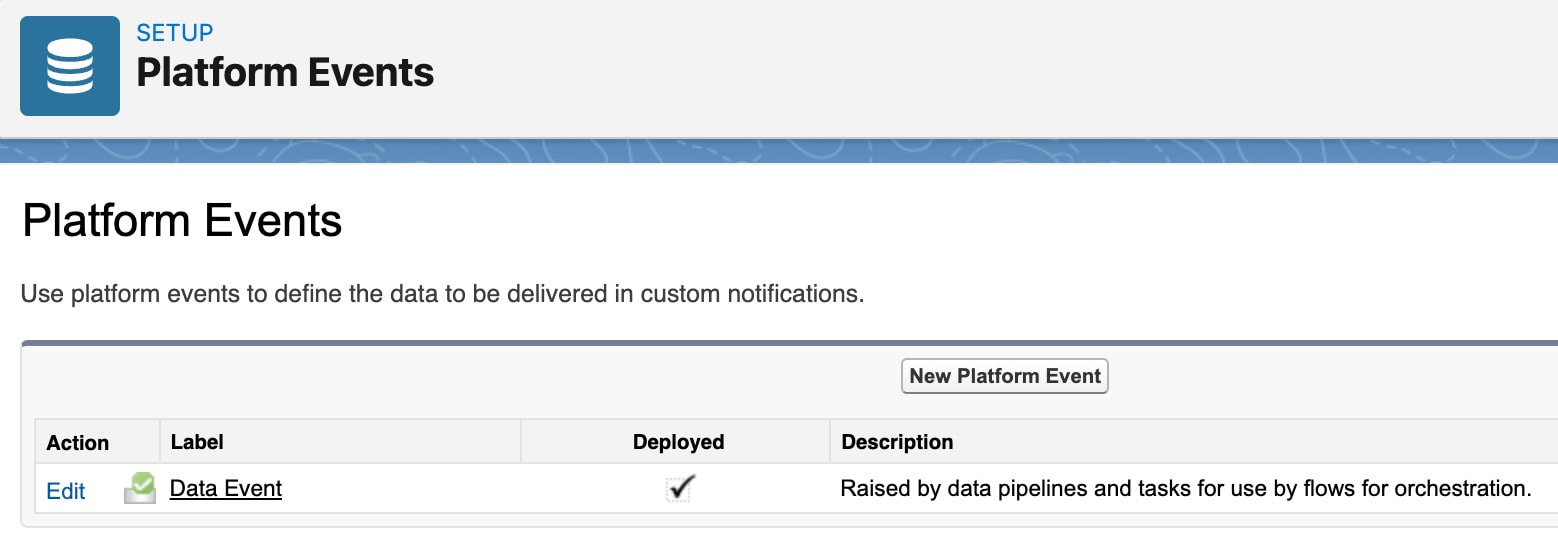
Platform Events : Event-Based Architecture
|
Cubic Compass utilizes an event-based architecture that raises a platform event for milestone within any data pipeline, data task, snapshot, or deployment.
Examples of events:
|
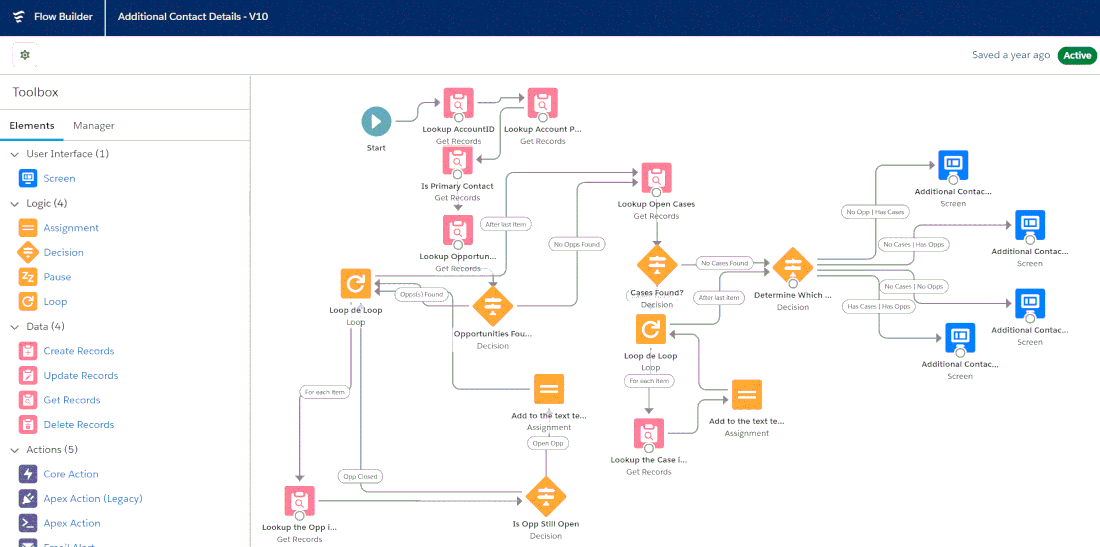
Data Flows : No-Code
|
Based on Salesforce Flows and Lightning Orchestrator, the Cubic Compass data management methodology encourages the use of platform event and record-trigger flows.
No-Code Data Processing Once connections and data lakes are established, any Salesforce Admin or Developer can implement 100% of data processing tasks in flows. No Apex or custom development required. Examples of event-driven data flows include:
|
|
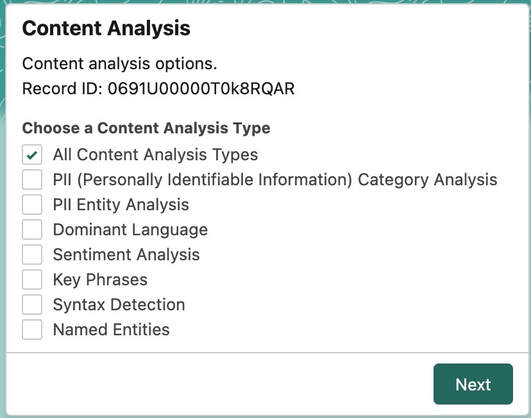
PII Data and Content Analysis
|
Analyze Salesforce Files and Attachments for PII (Personally Identifiable Information), dominant language, sentiment, key phrases, and other AI-driven content analysis services.
|
Apex and Java Extensions
|
For the "last mile" in complex or highly engineered integrations, Apex and Java Eclipse extensions are provided for hands-on coding.
Best practice is to wrap complex data processes in Apex invocable actions for use in the no-code flow builder environment. This creates the best of both worlds with reusable API components that make callouts for data, and flows to handle and process the data. This also provides a clean delegation of responsibilities when building data-driven teams. |

|
Logging, Reports, and Dashboards
|
All data task activities are logged to an event log for use in standard reports and dashboards.
Escalation and notification processes can be configured to auto-retry or notify users when data task exceptions occur. |